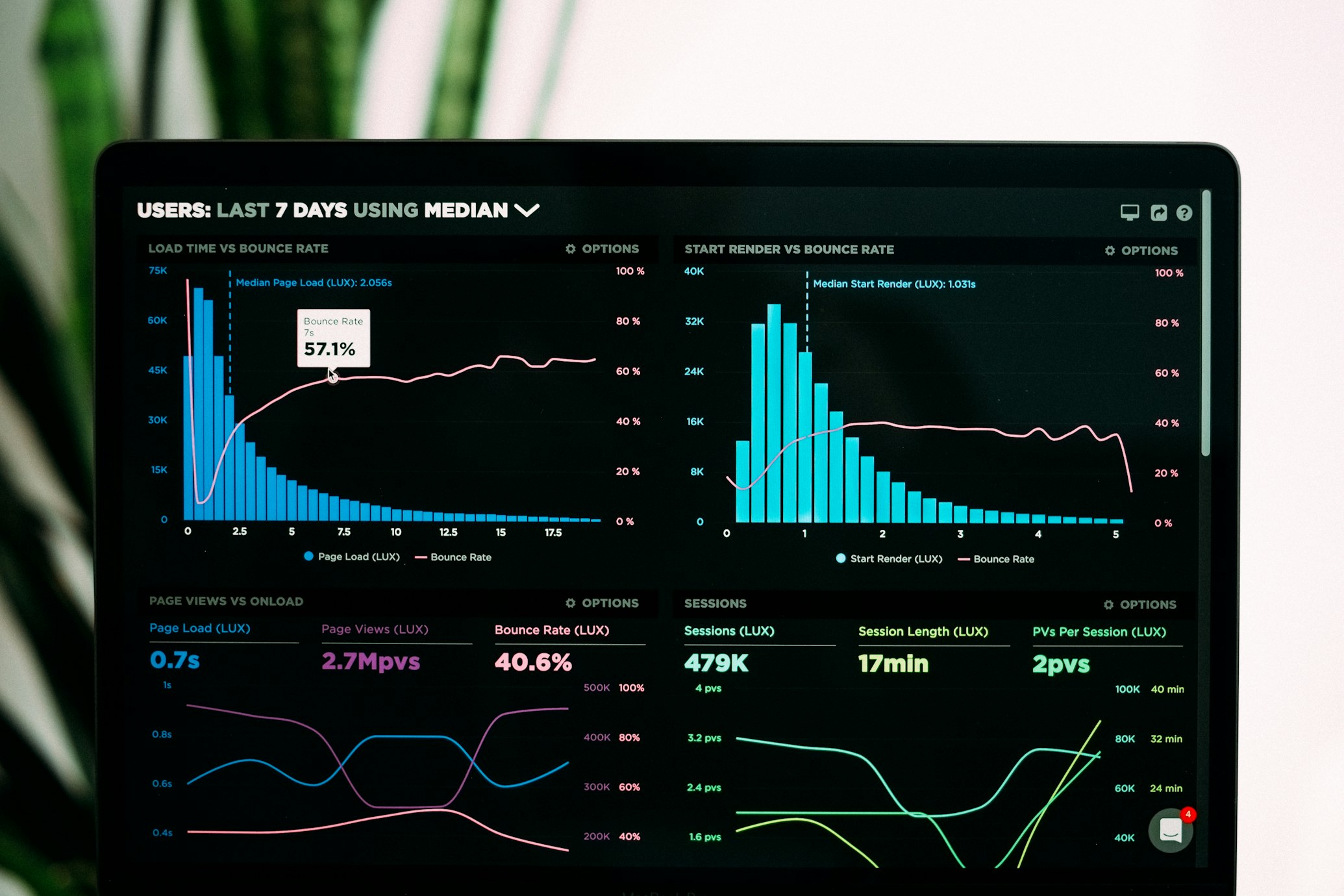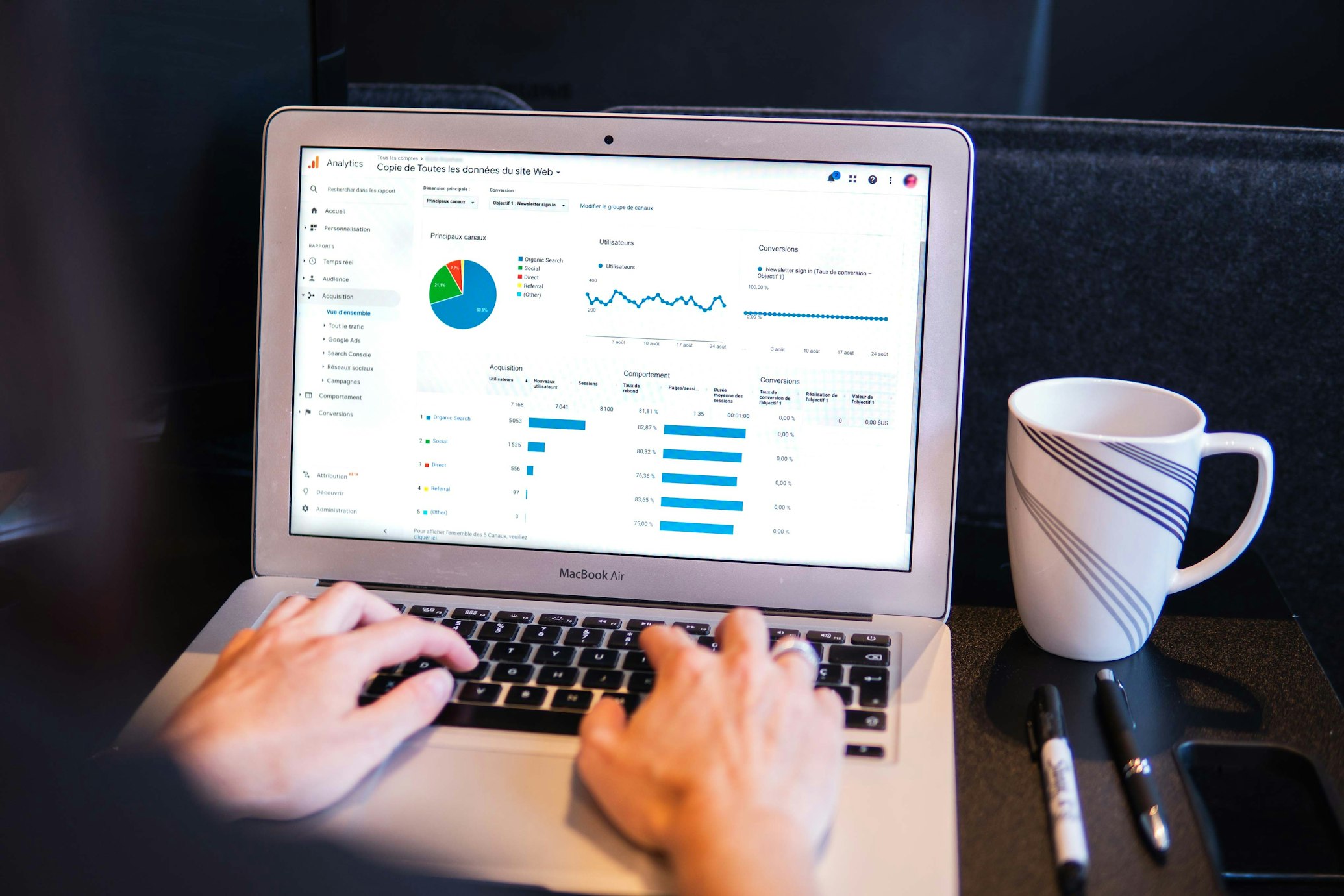
Data science is all about solving real-world problems. Here's a concise guide to tackling projects from start to finish:
Understand the goal. Engage with stakeholders to uncover their needs and translate business problems into data science questions. Define success metrics (e.g., accuracy, revenue growth).
Find and gather relevant data from sources like databases, APIs, or web scraping. Secure raw data as the foundation for your analysis.
Tidy up the data. Handle missing values, fix inconsistencies, scale features, and encode categories. Create new features if needed. Clean data = better insights.
Dive into the data to uncover patterns and trends. Use visualizations to identify relationships, outliers, and hidden insights that guide your next steps.
Focus on the most relevant variables. Create or refine features that add value, and reduce noise to boost model performance.
Train machine learning models. Experiment with algorithms, tune hyperparameters, and evaluate performance using training and testing data.
Validate the model's effectiveness on unseen data. Use metrics like accuracy, precision, and recall to ensure robustness and avoid overfitting.
Integrate the trained model into production environments. Ensure it runs smoothly with real-time data to deliver actionable outcomes.
Monitor performance post-deployment. Data evolves—keep your model updated to stay relevant and reliable.
Share insights effectively with stakeholders. Use reports, presentations, and dashboards to highlight the value your work delivers.
Whether you're building a fraud detection system or a recommendation engine, following these steps ensures a structured and impactful approach. Let's drive innovation through data! 🚀